 SDI video contains a maximum of 16-channels of audio. This has traditionally been a limiting factor in productions requiring large numbers of audio tracks such as numerous languages. ST-2110, being IP based, does not have such limitations. A decoder, for example, could choose to output more than 16-channels of audio. This blog post will explain how we have overcome this limitation and why a software-based architecture makes this possible.
SDI video contains a maximum of 16-channels of audio. This has traditionally been a limiting factor in productions requiring large numbers of audio tracks such as numerous languages. ST-2110, being IP based, does not have such limitations. A decoder, for example, could choose to output more than 16-channels of audio. This blog post will explain how we have overcome this limitation and why a software-based architecture makes this possible.
Overcoming the 16-Channel Limitation: The Traditional Way
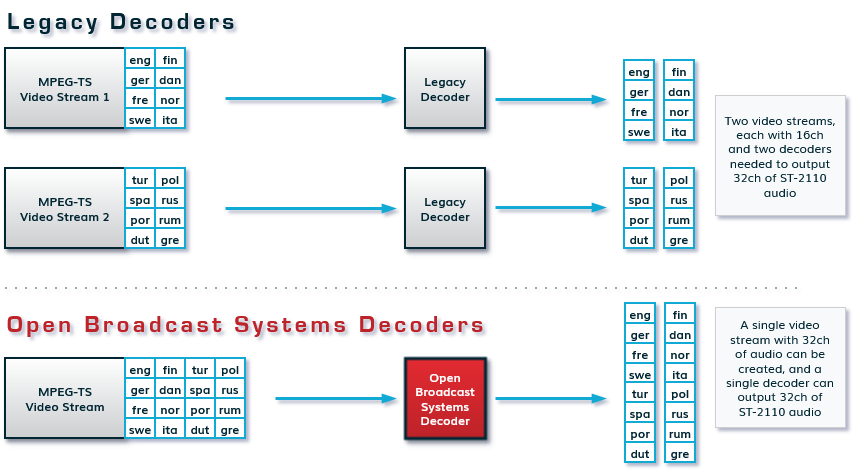
Yet despite the possibilities offered by ST-2110, most encoders and decoders remain limited to handling only 16 channels of audio. When a production needs to compress and transport more than 16 audio channels, they get around the problem by sending two separate video feeds, each limited to a maximum of 16 channels . But compressing an extra video feed just to enable extra language channels introduces unnecessary complexity into the workflow. This escalates costs, as operations must deploy two encoders and two decoders instead of a single pair, driving up resource requirements. More hardware, infrastructure, and bandwidth is required. This is shown in the diagram above. In addition, it’s tricky to maintain precise phase alignment between the audio tracks coming from different feeds.
However, a better approach is possible. What if a single encoder/decoder pair could overcome the legacy, SDI-based limitations, and handle 32 audio channels?
That is what we have done. Recently, we added support for more than 16-channels of audio in our low-latency encoders and decoders.
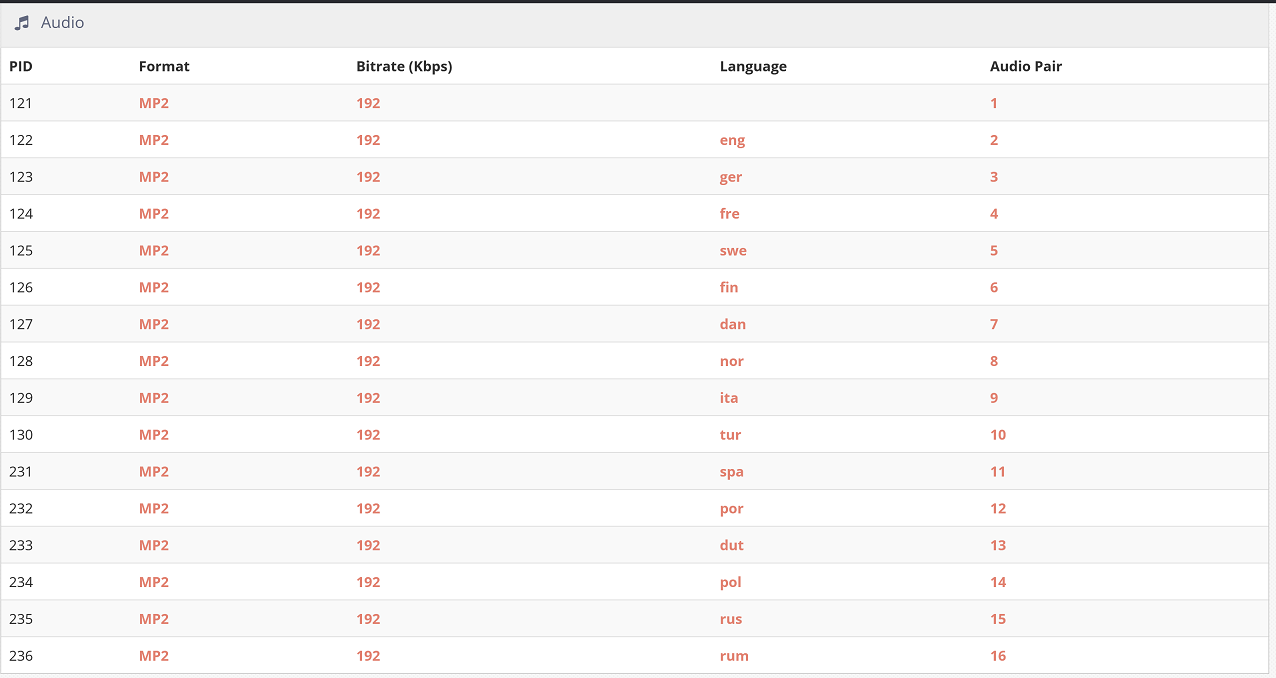
The following screenshot shows this in action. This large transport stream has numerous languages and we are decoding more than eight pairs to ST-2110:
 The “embedded” nightmare of 16-channels
The “embedded” nightmare of 16-channels
But why is adding more than 16-channels of audio even a big deal? As we have written about before, most products in the broadcast industry are built around “embedded” principles with relatively fixed function designs. In many cases ST-2110 has been retrofitted into legacy SDI based designs with the same 16-channel limitations. In the case of encoders and decoders the limitations can be explained by one or more of the following factors:
- Lack of DSP audio processing modules – some products use DSP processing modules to encode or decode audio. Almost always, the manufacturer doing this puts only enough for 16-channels of audio per SDI stream.
- CPU too weak to process audio – some hardware vendors use a very weak “embedded” CPU to encode or decode audio, in addition to rendering web pages and processing packets. In embedded designs, this CPU is often too weak to (de)compress audio.
- FPGA lacking processing capabilities to process the audio – in embedded designs an FPGA is used to create the audio flows. Only a handful of embedded products support more than one flow of audio as creating additional flows uses FPGA resources. (see our previous blog post, Understanding ST 2110 Audio Terminology: Flows, Channels, and Levels A, B, C). Ideally, we would like to send 16 or 32 stereo pairs (32 or 64 channels respectively) in ST-2110.
Software to the rescue
A pure software design changes this. The CPUs we use are tens of thousands of times faster than the CPUs used by embedded manufacturers. This means (de)compressing the audio tracks is trivial and adding more audio flows is substantially easier as we have plenty of CPU headroom.
A pure software design allows for rapidly adding new features such as more ST-2110 audio tracks. As the first vendor to support 200 Gigabit and now the first vendor to support more than 16-channels of audio, we are demonstrating this.
Learn more about our encoders and decoders: https://www.obe.tv/portfolio/encoding-and-decoding/
